
Despite the growing trend of Model-based software development (MBD) in automotive, an important part of the embedded software is still developed as handwritten code. People often move to MBD for new projects or when new complex functions are introduce. Several factors explain the remaining hand-code part such as: existing legacy code proven in use, experienced hand coding engineers present in the companies, big challenges to reverse-engineer handwritten code into models, and of course low-level software which are difficult to develop with MBD. Although, writing embedded code in C is as old as the language itself, the verification process is constantly looking for improvements. On the process side, new safety standards like ISO 26262 requires a qualified verification tool for ASIL rated software and for the daily work, engineers look for solutions with less manual effort for unit testing C code.
Compared to MBD, handwritten code has a very low degree of abstraction. It’s often difficult to identify which function to test and which variable to access in a bunch of source files. It’s even harder to isolate the function for testing when it has many dependencies. In this context, we identify three main challenges:
- The recurrent need to create stub code for external variables and functions
- The extraction of an architecture view of the test interfaces of each function
- The creation of the test harness to write, execute and evaluate test cases
1 - Stubbing
Software units have inter-dependencies through the data they exchange and sometimes extra-dependencies with sub-components like library functions, services or hardware routines, plus the architecture is often distributed in several files. To perform unit test, the unit has to be “isolated” from the rest and this process sometimes requires to create stub code for the variables and functions owned by other units.
How easy it is to create stubs?
Let’s compare two types of software architectures:
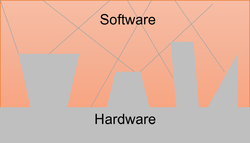
a. A cluttered software architecture where the frontier between the software and the hardware layers cannot be well identified (e.g. direct call of low level hardware routines within the software units) nor the frontier between the software units (e.g. unit owning variables accessed by other units)
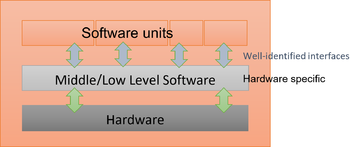
b. In opposite, a structured software architecture where the software units are separated and communicate through well-defined interface variables not owned by the units themselves and where a middle abstraction layer creates the interface between the software and the hardware
With option a, the access to hardware functions within the unit makes it almost impossible to test the unit without the hardware. Units owning the definition of interface variables create cascaded dependencies which requires to carry several files when testing other units. Such architecture style increases the stubbing effort as it’s difficult to find the cutting layer from where files, variables and functions can be stubbed.
Option b in contrary, enables to develop and test the units individually and significantly reduces the stubbing effort. For example, if the interface layer is not yet or only partially developed, the missing interface variables (external to the units) can easily be stubbed in a temporary file without altering the production code.
In a distributed development process, software units are developed by several teams in parallels and some parts of the architecture are only available at the final integration phase. Therefore, stub code is often needed. An appropriate software architecture such as option b helps to reduce the stubbing effort for more efficiency.
Nevertheless, the stubbing process itself can have some complexity depending on the data to be stubbed. Here are some examples:
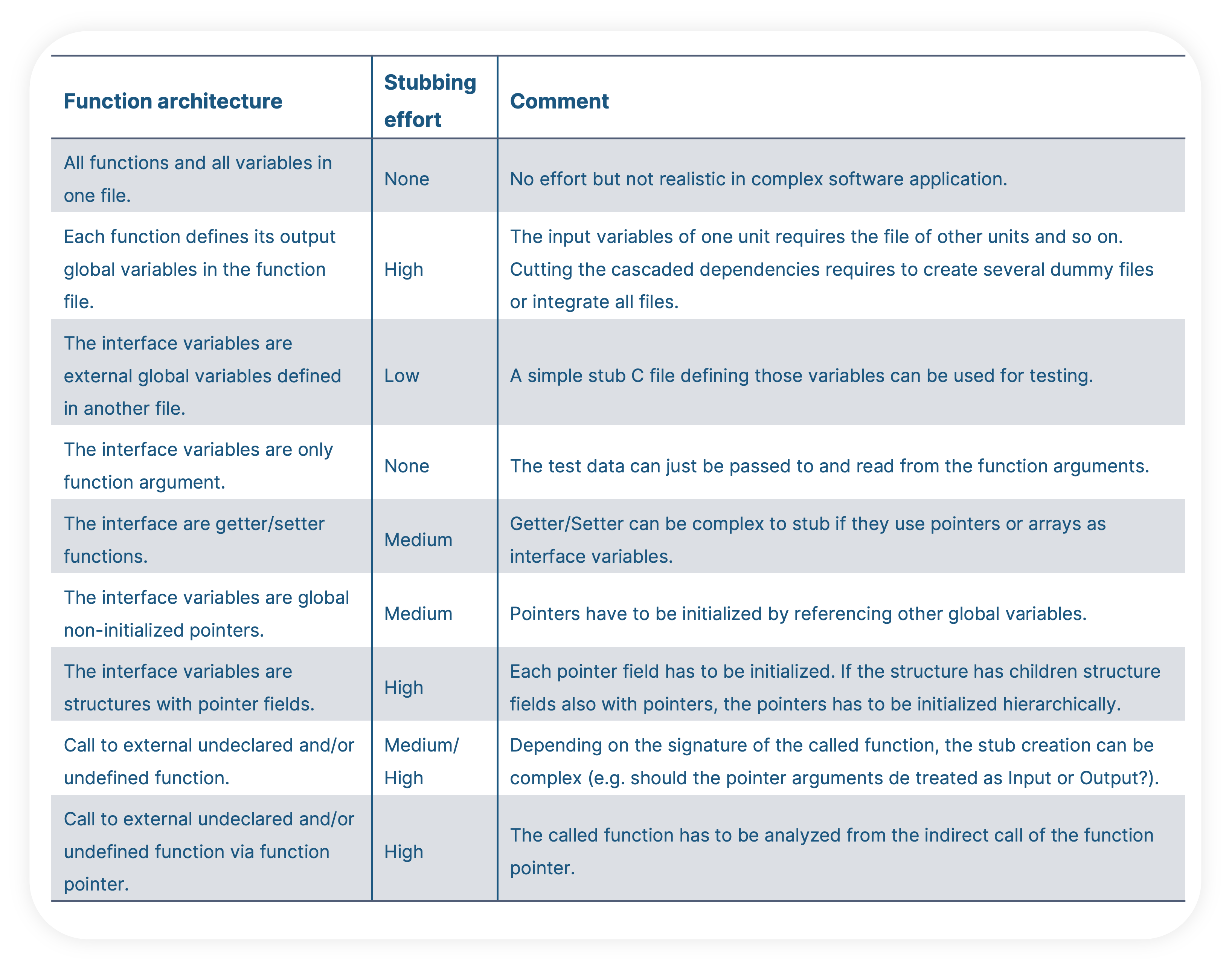
Stubbing effort while unit testing C code
To conclude, once stubbing is possible, it can be handled through an automated process assisted by tool. The correctness and accuracy of the stub code depends on the tools capability to identify the inter-dependencies within the set of source files. With BTC EmbeddedPlatform for instance, the stubbing feature proceeds through an exhaustive parsing of the c-code to detect undefined variables and functions and offer to create stub code from a simple push button. This includes stub code for variables, arrays, pointer initialization, function pointers and complex data such as nested structures.
2 - Architecture definition
For the next step, let’s assume we have a software unit with a self-contained set of source files (including potential stub code) and ready for testing. Before starting, two questions pop up:
- What are the input and output variables of the unit and how to access them?
- Are there any sub-functions within the unit we should also consider during testing?
Interface variables
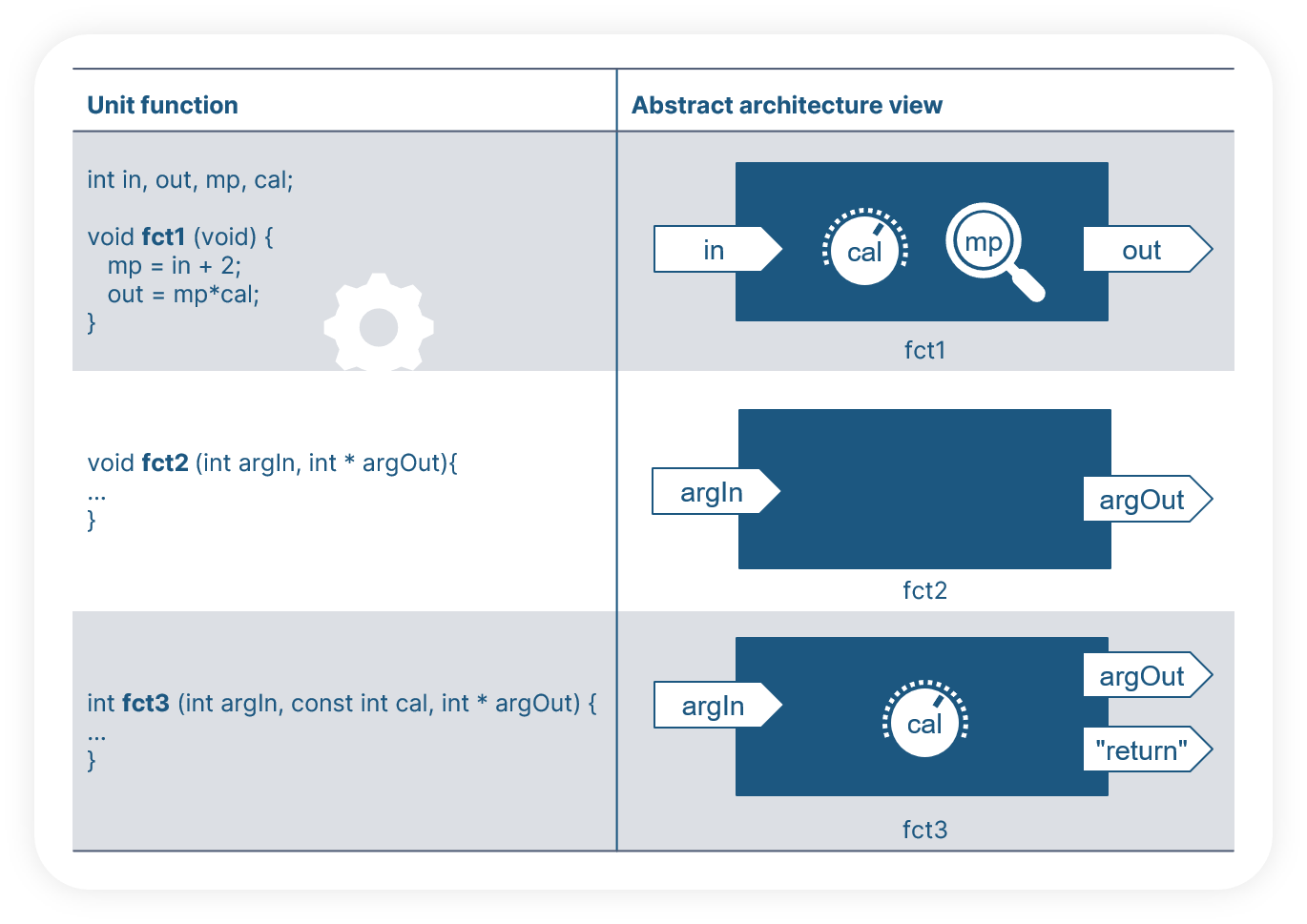
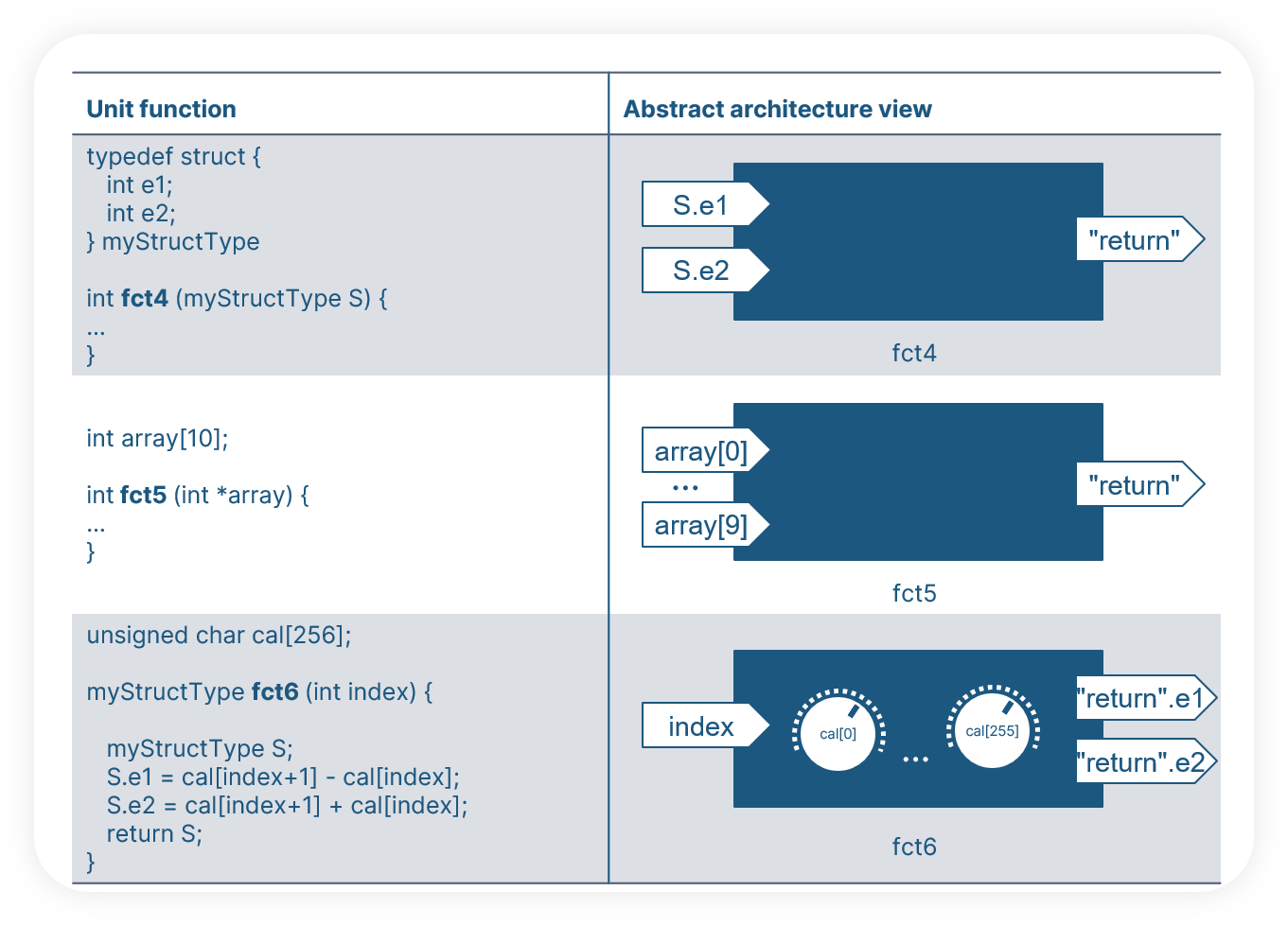
In model-based development, the interface variables of the software unit are omnipresent as given by the model structure (e.g. ports of a subsystem) but in handwritten code the information is not easy to find. The interface variables can be function arguments, global variables, getter/setter functions, macros, elements of composite data like structures or a mix of all these. They can be defined in any file and at any line of the code. Reading the code to find interface information is not realistic. Instead, test engineers should use an automated solution to extract the information as form of an abstract architecture view (a kind of box with Inputs/Outputs). No matter which variable construct the function uses as interface, the abstract view of the test interfaces helps the tester to know which variables stimulate the function and which ones can be evaluated. In general, the software units have four types of interfaces:
- Input variables: signal received by the unit under test (produced by another unit)
- Output variables: signal produced by the unit under test
- Calibration variables: variables used for software configuration
- Measurement variables: variables inside the unit allowing to measure inner operation results usually for debugging purpose. During unit test they are treated similar as outputs.
In the following examples, we see various definition of function interfaces. For the test engineer, the abstract architecture view (in the right-hand column) is more self-explaining then the code itself.
Function hierarchy
Complex or large software units are often split into smaller functions. The goal is to group functional operations into sub parts to break down the complexity. This can be a design choice of the developer, or a constraint derived from the software requirements (e.g. pre or post processing of data, reusable operations, etc.). It helps to develop the function step by step and to test functions with relatively small sizes and then proceed hierarchically towards the highest level. In addition, the hierarchical testing eases the debugging tasks as errors can be narrowed down to a small area of the unit.
Just as for the interface variables, it can be difficult to find the function hierarchy by just looking at the c code. An abstract architecture view (extracted automatically like a call graph) is much easier to read and understand.
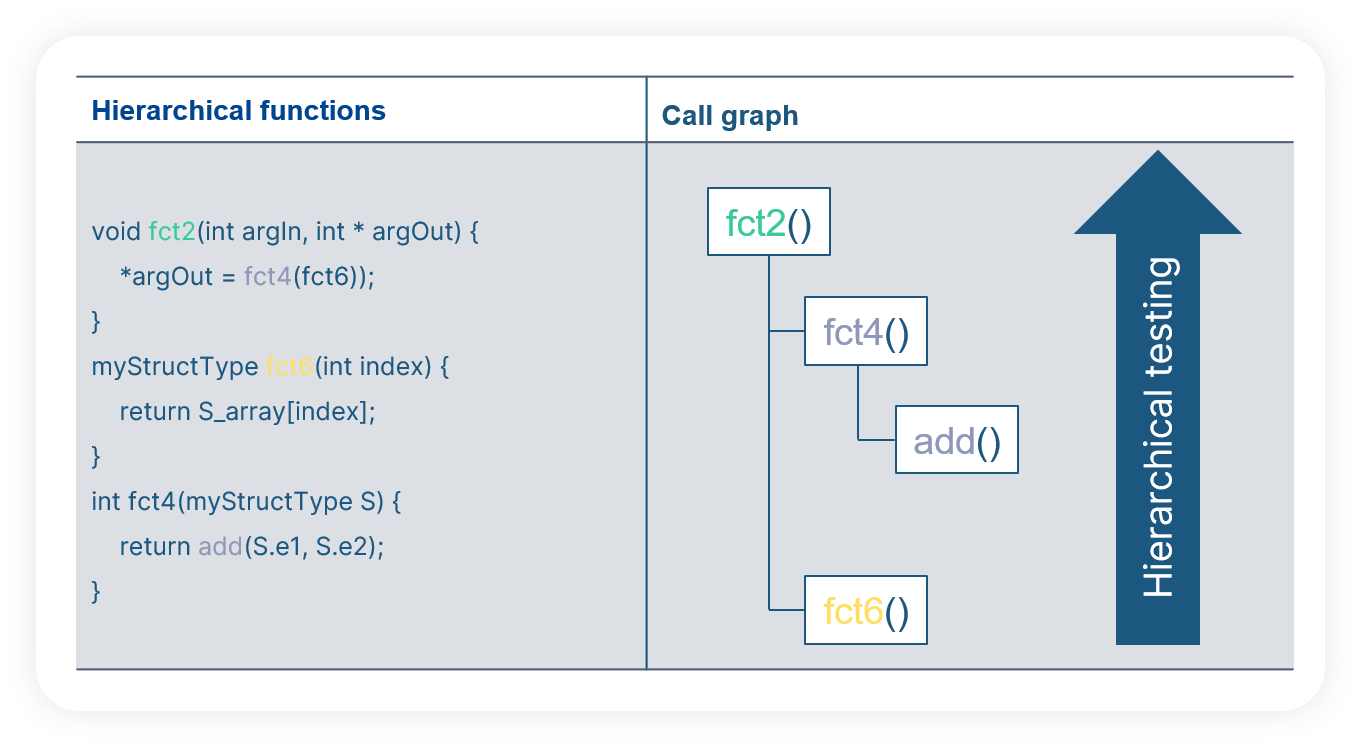
With BTC EmbeddedPlatform, an automatic analysis of the source code can find all functions and the hierarchical calls between them. This is presented in a call graph where the test engineer can choose which function to test. In addition, the interface variables of each function are analyzed automatically and made accessible in the test cases. The user can adjust the analyzed interface definition or overwrite it from external data base describing the I/Os of the function.
3 - Test Harness
The test harness is the executable part of a test tool that connects the function-under-test, the test cases, the compiler, and further methods (or tools) to evaluate the test results.
Often, unit testing of C code uses handwritten code to test handwritten code. This is possible with many testing frameworks including standard Integrated Development Environment (IDE) such as Microsoft Visual Studio or Eclipse. However, setting up an IDE test project can be time consuming and error prone. The abstraction view of the function-under-test is missing, and the test engineer must manually find the functions and interface variables to access. The convenience for writing and evaluating the test cases in IDEs is very low compared to a graphical user interface, plus many other aspects such as test management, coverage analysis, traceability with the requirements require to integrate with third party tools or plugins.
Ideally and among other features, an efficient test harness should be able to automatically handle variable scaling (e.g. fixed-point datatype) to support test values written in the physical domain. It should enable mathematical signals creation including time dimension and the definition of tolerances and more complex verdict mechanism to evaluate the test results, and finally, it should be able to execute several test cases automatically to calculate an aggregated result.
As the manual approach to create a test harness is error-prone, any mistake can have a direct impact on the test result. Therefore, we recommend using professional tool to test complex and safety critical functions. The professional test tool would typically be able to automatically create the test harness from an abstract architecture definition and prepare the test interfaces for a ready-to-use project. This can considerably speed up the test process and improve the quality of the testing activities.
Conclusion: Abstraction and automation are testers’ best friends
Unit testing C code is possible with several IDEs including open source tools but for complex software functions, testing goes beyond a simple gathering and compilation of source files. An efficient testing process needs a “well” defined software architecture combined with maximum automation and sufficient abstraction for the test authoring. Automatic stubbing is a handy feature to manage external dependencies. An abstract architecture view of the functions and interfaces offers a “system” view which helps to connect the function-under-test, the software requirements and the test cases. The automatic creation of the test harness, without user interaction, is the highest added value feature for a test engineer. Once available, test cases can be immediately created and executed. In addition, we should not ignore other aspects such as test management, coverage measurement, reporting and debugging required to address modern software development. At BTC, we try to solve these challenges with our integrated test tool BTC EmbeddedPlatform.

