
Toolchains in model-based automotive development projects
No doubt, model-based development (MBD) projects offer a lot of benefits for automotive embedded software development, especially in the mechatronics-focused domains. However, compared to classic software development which mostly relies on a compiler, maybe a build tool plus some libraries for testing, checks, etc., MBD is guaranteed to come with a heavy Windows-based toolchain from the vast MATLAB Simulink ecosystem.
To complicate things even further, these toolchains are usually entirely different for each company:
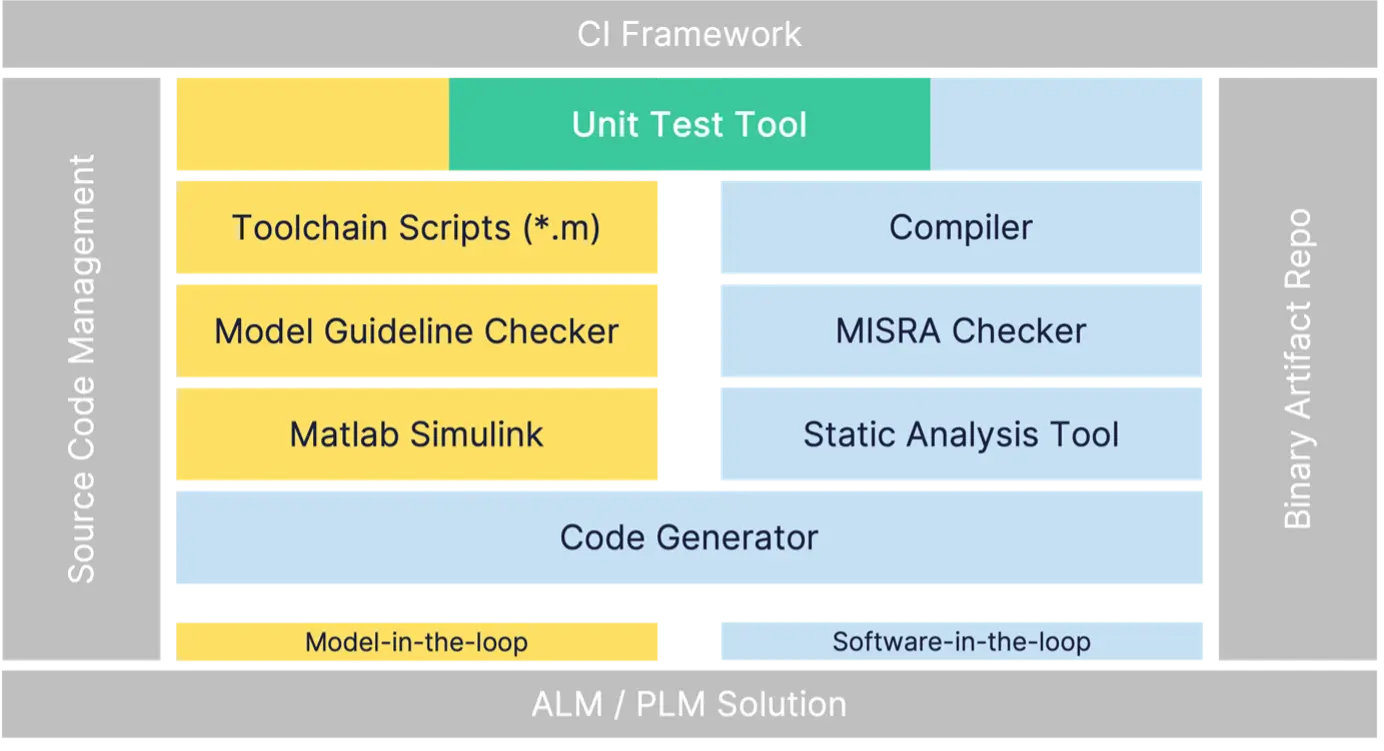
Consequently, there is no standard toolchain package or standard CI pipeline, let alone an off-the-shelf Amazon EC2 or AzureVM template. But we still don’t want to be forced to install 10 different tools whenever we provide a CI runner or developer VM. We need a solution that is easy to use, easy to rollout to CI runners, and easy to maintain.
Using Virtual Machines to ensure a consistent environment
Virtual machines seem to be the perfect fit. They provide a nice, sandboxed environment and – when working in a managed solution like Amazon EC2 or AzureVM or applying tools like Chef, Puppet, Ansible or Terraform – you can prepare VM templates that can be rolled out at scale.
This provides a huge benefit, as VM templates can be prepared by a central team – even allowing manual adaptions – and then be rolled out both as developer VMs and as CI unners. Keeping both worlds identical is a great advantage, especially when developers need to debug failed CI runs.
However, the flexibility of VMs is also a big weakness: humans naturally seek the path of least resistance and if something can be solved by a manual tweak, we will utilize that. Consequently, it’s hard to know the cause when the VMs suddenly act up after a roll out. Has someone forgotten an essential manual step? Or was the VM corrupted after the rollout – permanently modified by an application running inside it?
Broken access rights, missing or modified environment variables, or a full disk due to missing clean up routines are just some of the many things that tend to go wrong when VMs are deployed at scale.
This can be mitigated partially by applying a strict configuration-as-code approach; however, this usually requires additional management solutions. I’ve worked in projects where the solution was a nightly reset of VMs, to ensure that their state doesn’t stray too far from the original state, but in my opinion, those nightly resets were causing more problems than they solved.
A system should either stay the way that I left it or be entirely ephemeral. But a mix of these concepts leads to situations where it’s sometimes working great, sometimes slightly off, and at other times completely broken.
And to make things worse, having VMs constantly active in the cloud is very costly, with an especially bad cost-benefit ratio at times where they are idling, as Windows tends to make sure that the CPU doesn’t get bored. On the other hand, treating VMs for CI runners as entirely ephemeral (start on demand and discard after use) solves most of those problems, but also comes at a high price:
- Big delays due to slow startup times (usually over 1 minute)
- High resource consumption on startup (unrelated to the actual workload)
- Compute, Memory and storage footprint increased by OS
Solving the pain-points with Docker Containers
The pain-points described above are not entirely new. For these exact reasons, containers have emerged as a leading solution.
If you’ve never heard of a container, feel free to google for a textbook explanation or consider the following perspective:
You can think of a virtual machine as a house. An application can run inside a VM the same way you can live in a house. The house has its own foundation, driveway, plumbing, central heating and utilities. If you run applications at scale using virtual machines, you duplicate all of that.
Similarly, you can think of a container as an apartment. You can also live in it, but not every apartment needs its own foundation, driveway, plumbing, central heating and utilities. When running applications at scale in containers, you basically operate a big student residence. The cheap rent this concept offers is directly reflected on your cloud bill 🤓
This already mitigates the problem of costly resource consumption overheads. But containers can do so much more! They are built from a text file recipe (the Dockerfile), which is kept in source control (configuration-as-code). This is important: changing the container means changing the Dockerfile and that means a commit to your git repository. In other words: it’s very easy to track changes and roll back a working state in case something breaks.
From the Dockerfile an immutable container image is built and stored in a container registry from where it can be accessed when needed. It starts up in a second, as the container shares the host’s kernel instead of having its own full-fledged operating system. This enables pretty much native performance and a minimal resource overhead while providing a well-defined sandbox environment for apps running in the container.
The only disadvantage: container technology was designed for Linux-based operating systems. While it’s also available on Windows, the experience is much smoother on Linux: This makes it harder to achieve environmental parity between CI and developer VMs (which are mostly Windows-based in automotive). But if anything, I would argue that a Linux-based container running your code using GCC is closer to your hardware target than a Windows server equipped with a Visual Studio compiler.
The only real deal-breaker can be the fact that your company’s toolchain includes tools that only run on Windows. But there’s a good chance that this doesn’t affect you: given the rising demand, most tool vendors in the industry have added Linux support in the last five years.
Putting it all together in an example
- MATLAB R2023b
- BTC EmbeddedPlatform 24.3p0
- GitHub Actions for CI
Our example has the following file structure:´
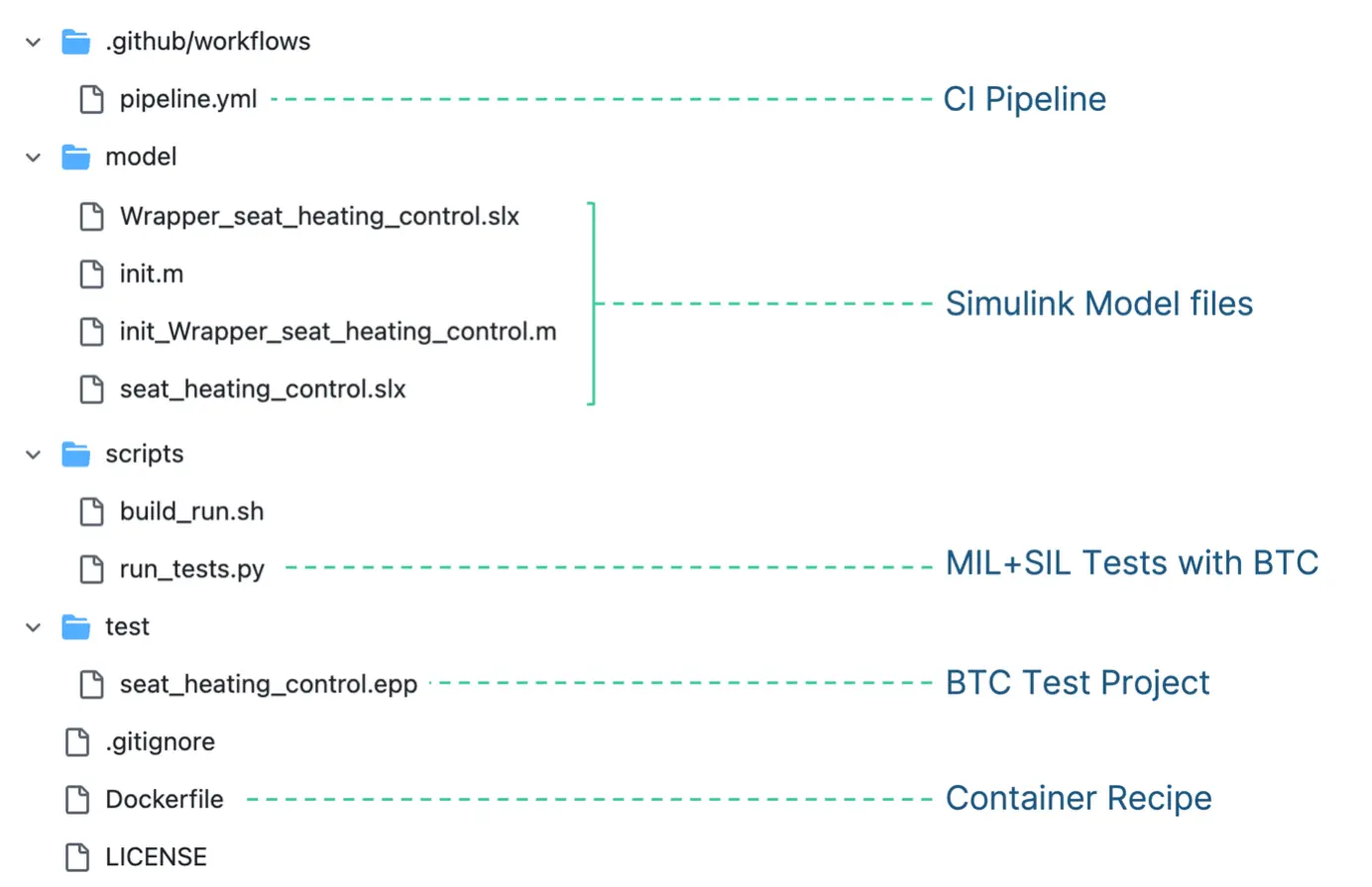
Our model is already working (=it compiles and can generate c-code) and we can run our tests using the Python script from the scripts-directory. But the script requires the necessary toolchain to be available. Our goal for this example is to be able to say “run my tests on model and code” without requiring any software to be installed (except for Docker).
This is where the Dockerfile comes in as our recipe to define the required toolchain.
General approach: creating a container image
We will base our image on the official mathworks/matlab image and customize it to meet our needs, including adding BTC EmbeddedPlatform from the public image btces/ep. Most importantly, we’ll expose the tool versions as build arguments, so that we can easily adapt them whenever we want to switch tool versions:
ARG EP_RELEASE=24.2p0
ARG MATLAB_RELEASE=R2023b
FROM btces/ep:${EP_RELEASE} AS ep
FROM mathworks/matlab:${MATLAB_RELEASE} AS matlab
MATLAB-related steps
To customize MATLAB to our needs, we first use mpm (=matlab package manager) to setup the required products/toolboxes:
# ———————————————————————————
# MATLAB-specific configurations
# ———————————————————————————
# Install required matlab products & set up license
ARG MATLAB_RELEASE
ARG MATLAB_PRODUCTS=„Embedded_Coder AUTOSAR_Blockset MATLAB_Coder Simulink Simulink_Coder Simulink_Coverage Stateflow“
USER root
RUN apt update && apt-get install -y wget
RUN wget -q https://www.mathworks.com/mpm/glnxa64/mpm && chmod +x mpm \
&& ./mpm install \
–release=${MATLAB_RELEASE} \
–destination=/opt/matlab \
–products ${MATLAB_PRODUCTS} \
&& rm -f mpm /tmp/mathworks_root.log \
&& ln -f -s /opt/matlab/bin/matlab /usr/local/bin/matlab
# configure MATLAB license server
ENV MLM_LICENSE_FILE=27000@matlab.license.server
At the time of writing, the MATLAB images no longer shipped a compiler, so we’ll add gcc:
# mex-compiler: gcc 11
RUN export DEBIAN_FRONTEND=noninteractive && apt-get install -y gcc-11 && update-alternatives –install /usr/bin/gcc gcc /usr/bin/gcc-11 100 && update-alternatives –config gcc && apt-get install -y g++-11 && update-alternatives –install /usr/bin/g++ g++ /usr/bin/g++-11 100 && update-alternatives –config g++ && apt-get install -y cpp-11 && update-alternatives –install /usr/bin/cpp cpp /usr/bin/cpp-11 100 && update-alternatives –config cpp
MATLAB-related steps
Up next, we’ll add BTC EmbeddedPlatform from its public image and integrate it with MATLAB:
# ———————————————————————————
# BTC-specific configurations
# ———————————————————————————
# Copy files from public image btces/ep
COPY –chown=1000 –from=ep /opt /opt
COPY –chown=1000 –from=ep /root/.BTC /root/.BTC
# integrate BTC with MATLAB
RUN chmod +x /opt/ep/addMLIntegration.bash && /opt/ep/addMLIntegration.bash
# configure BTC license server
ENV LICENSE_LOCATION=27000@btc.license.server
# install python module btc_embedded
RUN pip3 install –no-cache-dir btc_embedded
ENV PYTHONUNBUFFERED=1
Finally, we restore the default user and ensure that we can pass a Python script as the entry point for this container by removing its default behavior (to start up MATLAB):
USER matlab
# Override default MATLAB entrypoint
ENTRYPOINT [ ]
CMD [ ]
Using the image
At the start of this section, we stated our goal:
[to be] able to say “run my tests on model and code” without requiring any software to be installed (except for Docker).
Based on the Dockerfile we defined, we can build our image with a simple Docker build (the image name “mbdtest” is arbitrary, you can pick any name you like):
docker build -t mbdtest .
We’ve now reached our goal, being able to run our tests with a simple Docker run call. We’ll also make the current directory available as the workdir to have access to our model files, scripts, etc.:
docker run –volume „$(pwd):/workdir“ –workdir „/workdir“ mbdtest python3 scripts/run_tests.py
Et voilà!
Finishing touches
The only change we do before we integrate this in a CI pipeline is to control the MATLAB and BTC versions via environment variables. That makes it trivial to switch to a different version:
docker build -t mbdtest:${EP_RELEASE}_${MATLAB_RELEASE} \
–build-arg EP_RELEASE=${EP_RELEASE} \
–build-arg MATLAB_RELEASE=${MATLAB_RELEASE} \
.
docker run –volume „$(pwd):/workdir“ \
–workdir „/workdir“ \
mbdtest:${EP_RELEASE}_${MATLAB_RELEASE} \
python3 scripts/run_tests.py
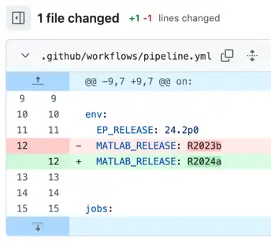
Below’s a screenshot of a pull request which switches the MATLAB version from R2023b to R2024a – this the beauty of a nicely prepared Dockerized workflow:
Conclusion
We’ve seen that both virtual machines as well as containers are capable of supporting the complex toolchains common in automotive software development and thereby enable scalable CI workflows in the cloud.
Virtual machines are the go-to solution for many, as they feel more natural to anyone who’s familiar with managing servers. Powerful template mechanisms enable a rollout of well-defined environments at scale, albeit without the benefit of immutability.
As more and more resources are hosted in the cloud, the underlying costs – previously often hidden – become apparent and reveal one of the major weaknesses of virtual machines at scale: the overhead of a full-fledged operating system. Mitigated only by running multiple workflows in the same VM which counteracts the goal of keeping independent workflows properly isolated.
Containers outshine VMs in most regards. Managing containerized application is much simpler than managing VMs, the startup time and resource footprint is as tiny, container images are immutable by design and encourage valuable practices such as “configuration-as-code” to ensure reproducibility at all times.
Personally, the only factors that I see in favor of VMs are the environmental parity of CI agents with the developer VMs (=common VM template) and the limited availability of some tools in Linux-based environments.
Update January 19th, 2025:
According to The Mathworks licensing conditions, running Matlab in a container requires a license that is „configured for cloud use“. Even though I don’t understand the rationals for distinguishing between container-based and VM-based automation from a licensing point of view, it is a relevant factor to consider.
Thanks to Bavo Denys & Pieter Fort for bringing this to my attention.

