
Vocabulary: Floating-point code? - Fixed-point code? – Scaling? – Resolution? – LSB?
Basically, we can distinguish between two kinds of datatypes in embedded code: Floating-point and Integer. An integer variable basically represents whole numbers and the value range is limited by the number of bits. For example, an (unsigned) 8bit Integer can represent 2^8=256 different values, by default ranging from 0 to 255. In contrast to this, a floating-point variable has some bits representing the significand and some bits representing the exponent in kind of scientific notation, which leads to a large data range.

But what is fixed-point? Fixed-point is a special type of Integer variables, which have a scaling. So what’s Scaling? It means that the resolution is not 1 but rather another value defined by the user. But what’s Resolution? It is the difference between two values if just the last bit is changing. That’s why sometimes the resolution is also called LSB, which means “least significant bit”. (Fun fact: In France they call scaling “mise à l’echelle” which translates to “putting it on a ladder”. Much easier to visualize this way).
As a result, for fixed-point variables we can distinguish between a physical value and an integer value. As there is also the possibility to define an offset, the formula looks like this:
Physical Value = Integer Value * Resolution + Offset
As an example, let’s look at two variables which have different scalings (second fun fact: In France, variables in a code example are not called foo and bar but toto and titi. Yes. It’s true.):
- toto has a resolution of 0.1, so a physical value of 15 would lead to an integer value of 150
- titi has a resolution of 0.5, so a physical value of 12 would lead to an integer value of 24
If we want to combine these two variables in a mathematic operation in our production code, we would first need to align the scaling, also taking the scaling of the target variable into account. Let’s build a sum and store the result in a variable result which has a resolution of 0.1:
result= toto + titi*5
This means, that in order to calculate the sum, we also have to perform a multiplication. This is why for optimization reasons, resolutions are sometimes defined as a power of two (e.g. 2-3 ). In this case, all the additional multiplications coming from adapting the resolution can be implemented using bitshift operations (e.g. going from 2-2 to 2-5 can be implemented realized by shifting the bits 3 digits to the left: titi<<3).
One more thing: Ranges and Headroom. Whenever we define a scaling/resolution together with a corresponding integer datatype, we also define how we represent this value range. Let’s say we have an Int8 Datatype and want to represent a temperature which can be between 0° and 25°. We can then pick a resolution of LSB=0,1 which lead to a data range of min=0° and max=25,5°. But what if the actual value gets higher than 25,5°? This could happen for multiple reasons, maybe we underestimated the maximum value of this variable or maybe there is just some noise on the sensor signal. If the value gets higher, an overflow occurs which should be avoided.
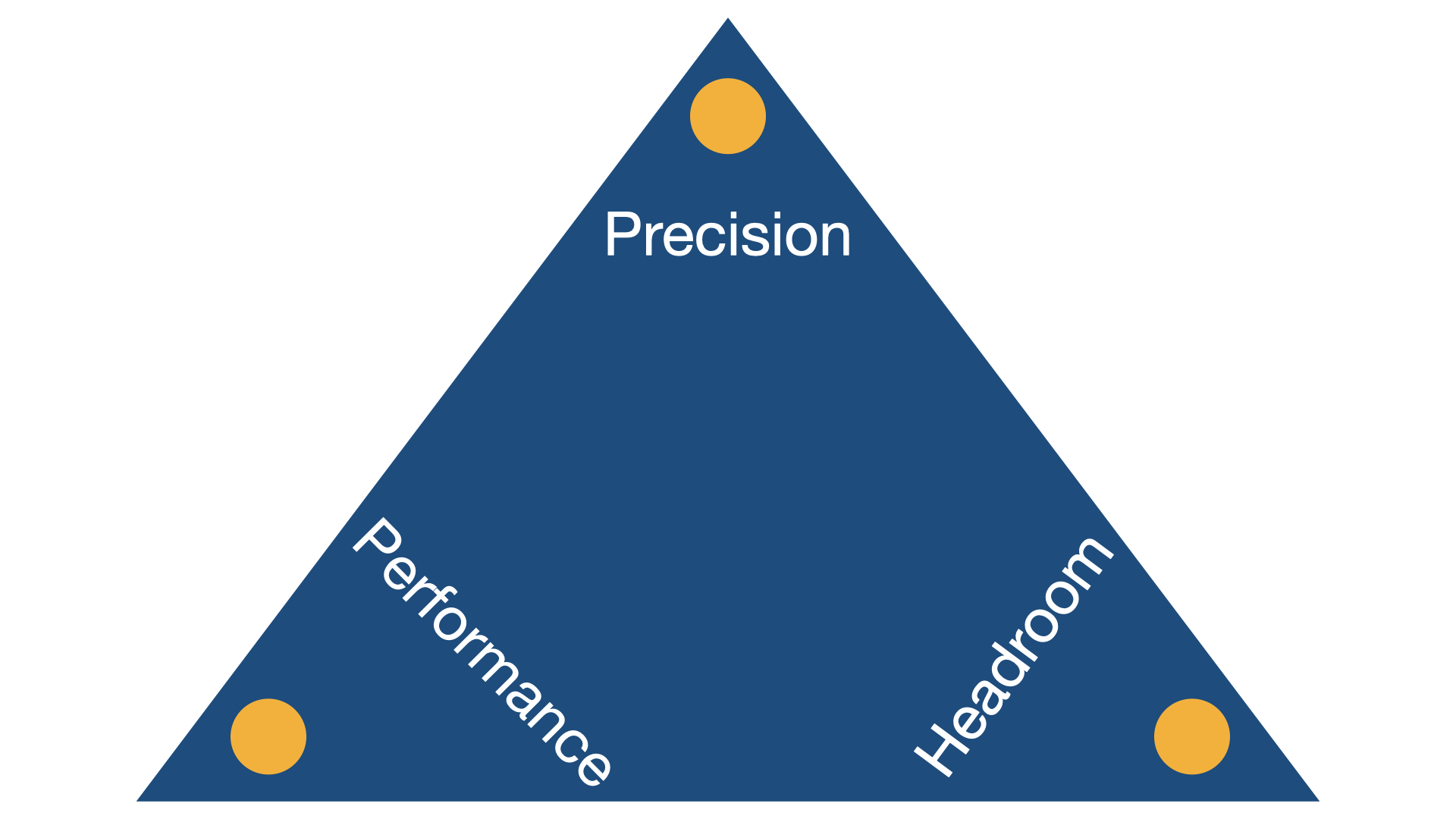
Finding the right scaling = Picking between three optimization goals
So how do you find the best scaling for your application? The sad news is, that there is no such thing as the ideal scaling. The task of scaling fixed-point code is always a compromise between three different goals which can never be achieved at the same time. And, it’s a compromise we are not just making once for the whole application, but per variable.
- Precision: Optimizing the precision of our calculations can be achieved by making the resolution as small as possible. First of all, we can make the resolution small if we pick an integer datatype with a lot of different states (e.g. Int32 with 2^32 different values). But compared to 8bit or 16bit data types, this would require more processing power which will have a negative impact on performance. We can also reduce the resolution if we choose a small headroom, but this makes the risk for overflows higher.
- Performance: If we want to get the best performance, we might pick an Int8 datatype, sacrificing on precision.
- Headroom: Optimizing for headroom means to make the implemented value range much larger than the expected min/max values. But as discussed before, increasing the data range will have a negative impact on the resolution and therefore on the precision.
How to handle fixed-point code efficiently
- Use a code generator
If we have to handle different variables with different scaling in our application, it can become quite challenging to manually define all the additional scaling operations (like multiplications and or bitshifts). Using an automatic code generator like dSPACE TargetLink or Embedded Coder, allows us to focus on defining our algorithm in the physical domain while the code generator takes care of the fixed-point code operations. It’s also very easy to automatically update the code should the scaling of one or more of the variables change. For handwritten code, we’d need to identify all locations in the code where these variables are used in order to modify them.
- Get some help to find the right scaling
There are mainly two techniques to (at least partially) automate the scaling configuration (e.g. provided by dSPACE TargetLink). The first one is range propagation. Based on user-defined input ranges and data types, the algorithm will try to calculate the worst-case ranges of all internal variables and set the scaling accordingly. For example, if our algorithm calculates the sum of two inputs with range [0 10], the variable for the result would get a worst-case range of [0 20]. This approach has risk of making the implemented ranges too large (because maybe the “worst case” of both inputs having the value 10 at the same time doesn’t occur). The second approach is simulation based. It uses test cases which are executed to observe the min/max values of each variable. This approach comes with the risk of making the implemented ranges too small, as maybe the test cases do not cover all possible ranges.
- Make sure that your test tool allows you to work with physical values
When working with fixed-point variables, it’s possible for a physical value of 25° to be represented by an integer value of 250 (with a resolution of LSB=0,1) or 800 (with a resolution of LSB=2-5). When writing a test case (or reviewing results), it’s always much easier to work with physical values as these are also the ones typically used in the requirements. So, our test tool should be able to represent both the physical values AND convert the value to the corresponding integer representation for code based simulations.
Come on, it’s 2020! Shouldn’t we all be doing floating-point code by now?
Not so fast. It is clearly true, that some years ago developers didn’t have much choice. Due to limited processing power and missing floating-point units in common embedded processors, the code had to be implemented in fixed-point. Today, many processors can handle floating-point and many developers believe that life gets easier. But there are also some misunderstandings when it comes to floating-point.
First, let’s acknowledge that floating-point variables do not have perfect mathematical accuracy, and in fact they also have a resolution. But, in contrast to fixed-point code, this resolution can’t be configured and it is not the same over the whole value range. For very large numbers the resolution actually is worse than for integer. So, if you have variables working in a clearly defined data range, fixed-point gives you actually more freedom to define and optimize the precision compared to floating-point.
Second, from a verification point of view, the mathematics of floating-point operations are often harder to understand and to debug compared to fixed-point. We can even have a different behavior depending on the compiler, which is typically not the case for fixed-point. Check out our blog article “What you should know about floating-point” for more details.
Conclusion
Fixed-point code basically uses integer datatypes together with a scaling. The scaling and the offset define the resolution of the variable leading to the physical value range which can be represented. Finding the right scaling means finding a compromise between precision, performance and headroom. By using a code generator like dSPACE TargetLink, we can get some help implementing the fixed-point operations in the production code and we can also get some help to find the right scaling. If we use floating-point variables, we can get rid of the scaling task, but this creates new challenges due to the fact that floating-point behavior can often be less transparent and predictable as compared to fixed-point.

